这是DFSS最后一步 Verify,总结内容如下。
可靠性是我学习DFSS才接触的知识点,很不错,同步阅读老师推荐的《基于Minitab的现代使用统计》的第二章“可靠性与生存分析”,加深本课程的内容,搭建更系统的可靠性知识。
几点总结:
- 可靠性是随时间变化的质量。
- 可靠性分析,最难的是如何量化,可靠性是与时间有关的特性。
- 可靠性分析,同样是“剥洋葱”的过程,逐层聚焦,先分析系统级别的可靠性,然后拆解成子系统和组件的可靠性,最后拆解到组成等层级。
- 衡量可靠性的函数:一种是与时间有关的函数,比如f(t), F(t), h(t), H(t), R(t);另外一种是统计参数,与测试时间无关,比如特定时间的可靠度R(完整测试后的合格产品/总产品)和MTTF(期望寿命)(完整测试后的样品寿命的平均值)。
- 使用“浴盆曲线”,解释瞬时失效率f(t)随时间的变化趋势,又分为上升期、平稳期、衰退期。
- 几种可靠性分析常用的分布类型:威布尔分布是应用最广泛的分布类型,适用于不同场景的可靠性;指数分布和正态分布都是威布尔分布的特例(固定beta值)。
- 这儿讲的分布函数,指的是谁的分布?例如指数分布y=e^(-λt),我们知道y的取值是(1->0),所以是可靠度R(t)=e^(-λt),随着t从初始值0到无穷大,可靠度R从1(全部合格)逐渐降到0(全部失效)。
- 可靠性设计时,尽量收集连续数据,比如失效时间、失效压力、失效时的掉落次数,等等; 尽量不用属性数据,比如通过/不通过; 尽可能将属性数据转化成连续数据。
- 组间可靠性对比: 可靠性对比,比之前的假设检验中的均值对比、方差对比要复杂,因为后者只是参数之间的比较。 但可靠性对比的参数是两组趋势之间的变化,对比参数是上一讲中的分布函数等。具体又可以细分成多种情况,比如两个产品之间可靠性对比,比如同一个产品的多种故障类型的对比。
- 系统可靠性,就像电路中的并联和串联结构,根据每个电阻计算整体的电阻值;假定每个部件的可靠性服从指数分布,可以很容易计算出串联系统和并联系统的可靠性。
- 系统可用性:
- 可靠性验证
与工作相关的思考
- 可靠性的收益是”潜在的、看不见的损失“,一旦产品可靠性没做好,就会带来很大的损失,或者需要打补丁解决新问题。越重要的产品越需要可靠性,比如风电、能源、医药、航空航天,这也是为何可靠性研究最早源自战斗机相关的研究。
- 尽量收集连续数据,或者尽量将属性数据转化成连续性变量。比如工作中测试某一款胶带能否通过静态挂重测试(holding power),合格条件是3天不脱落,但是有的样品没有通过该测试。分析原因时,只有每个样品合格与否,却没有具体的失效时的时间,这样就很难进行详细的问题分析。最后发现,能通过测试的样品3天后也能继续挂住很长时间,不能通过测试的样品都会在数小时内失效,而不是临近3天时失效。将这个可靠性问题转化成连续性数据分析,我们就不会将问题锁定在测试方法误差上,因为这是相当明显的系统性差异,而是将问题聚焦在测试材料上,一是胶带、而是贴合板材。
- 我现在做胶带产品开发,同样遇到很多可靠性问题,配方和产品看起来很好,但做储存稳定性达不到要求。这不能靠打补丁解决问题,而是要回溯到TD源头去解决,所以配方开发和产品开发要紧密合作,而PD要懂可靠性分析和根原因分析,才能避免肤浅的解决问题。
- 有些胶带产品的失效,就是可靠性不过关,比如客户贴50片,有20片合格,30片不合格;这样就是“可靠性分析”问题。
- 工作中有很多可靠性试验:比如高温高湿8585,比如40C/100%,比如胶带在40C和70C下的标准老化测试,
- 既然研究可靠性,就应该尝试建立产品的可靠性测试标准,用minitab分析实验中的可靠性数据,比如胶带在常温、40C和70C下的性能衰减曲线。
- 看到网上有专门的”可靠性工程师“岗位,可靠性确实是一个很重要的质量分支。现在各行各业的人才大都是只具有自己行业的经验和知识,缺乏通用的知识、思维和能力,缺乏通用技能,就浪费了专业知识。 可靠性就是一个”通用知识库“,适用于各种行业。 专业人才结合可靠性技能,可以成为一名行业内的可靠性专家。
关键词:可靠性分析,
可靠性应用课程简介

5.0 验证阶段概述 (第52讲)
目标:

可靠性设计(Design for Reliability,DFR)
5.1 可靠性应用
本课程介绍DFR中的分析、应用和验证内容,
1. 可靠性设计简介
可靠性设计(Design for Reliability,DFR):设计产品的可靠性以满足客户的要求。
可靠性是衡量产品质量的重要指标之一,通过将可靠性技术引入质量管理体系,大幅提高产品的质量。

可靠性设计:起源于欧美的战争和军工产业研究,航空和航天产品的开发,带动了可靠度的研究。很多产品因为可靠性不足而不能大规模推广,要通过应用和实战数据的分析,逐渐提高可靠性。
可靠性设计是不可或缺的一环,否则就会导致潜在的质量风险等。一旦出现事故,损失巨大,比如挑战者号航天飞机爆炸,比如三星手机电池爆炸事故等。
为什么可靠性很重要,可靠性研究对应于隐藏的风险,对于可靠性不足的产品来说,这些看不见的成本巨大,比如退货、声誉等。(想起了《一课经济学》,看得见的损失和看不见的损失!)
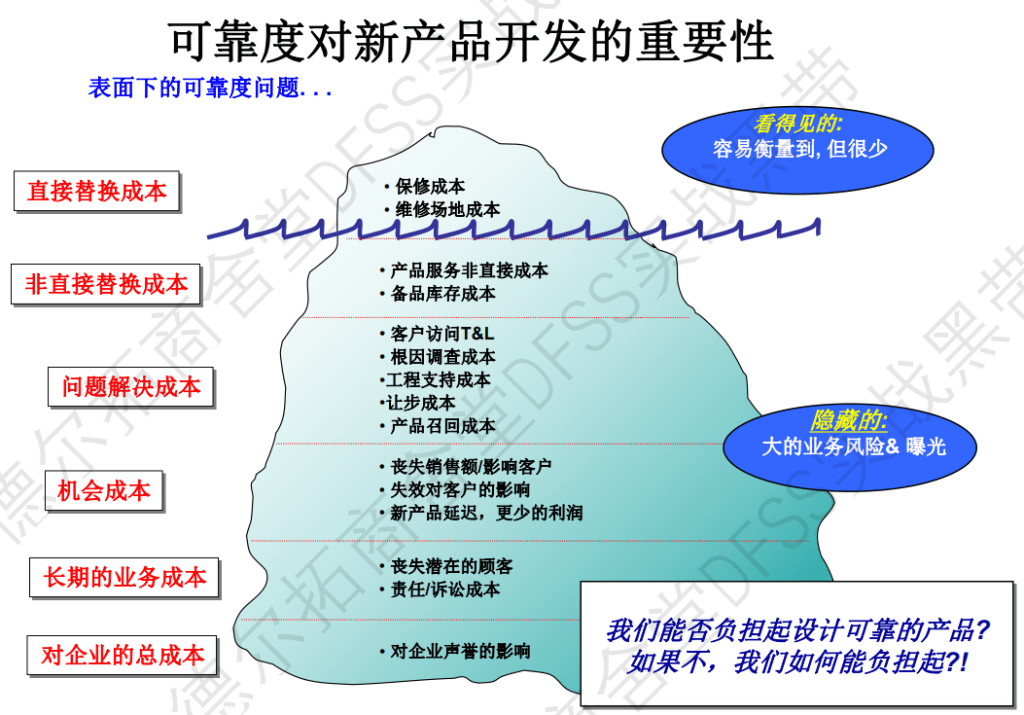
在客户满意度中,可靠度是最大的”小Y“。

2.可靠度定义与概念
可靠度建模、可靠度分析
可靠度的难点是如何测量,比如常规测量,破坏性测量,加速性老化测量等。

1987年Garvin就已经提出了质量八维度,其中包括了可靠性、一致性等,而不是我们最简单认为的“效能”和“感知质量”,同时还要看短期看不见的质量,比如可靠性、耐用性、服务能力,等。

可靠度展开的要求:可靠度需求必须转化成衡量指标,然后展开到团队成员。
如何进行可靠度展开,系统级—》子系统—》组件, 失效模型分析
可靠性设计工具(DFR)

可靠度:跟时间有关的质量!

可靠度的应用场景:
- 产品是否满足可靠度规定?
- 设计的变化
- 评估两种原材料对产品寿命的影响
- 预计产品保证的成本是多少
“失效”的定义:
- 定义:产品至少有一个功能不能使客户满意。
- 失效的5种可能失效模式
- 既定功能的部分缺失
- 功能达不到要求
- 既定功能退伙(随时间的老化)
- 既定功能间歇性缺失
- 出现非既定的功能(比如治疗心脏病的药,出现了其他的副作用或疗效)
可靠度的测量
- 根据目的和需求选择测量指标
- 可靠度函数
- 期望寿命(MTTF,MTBF)(对应可修复和不可修复的)
- 失效率和故障率含量
可靠度函数:

可靠度中的常用分布
- 指数分布
- 威布尔分布
- 正态分布
- 对数正态分布
可靠性试验中收集的数据类型
数据类型:属性数据,连续数据
可靠性设计时,尽量收集连续数据,比如失效时间、失效压力、失效时的掉落次数,等等; 尽量不用属性数据,比如通过/不通过; 尽可能将属性数据转化成连续数据。
课程中的一个例子,纸夹的寿命分析,不断重复折叠,记录每个纸夹失效时的折叠次数,这就是一个连续性变量(尽管只能取整数)。
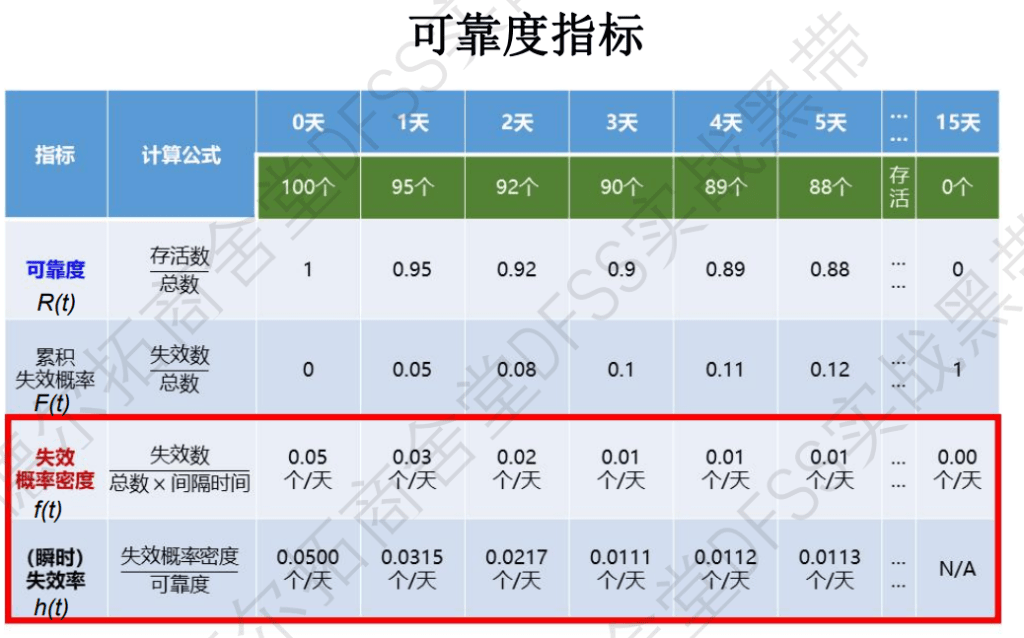
可靠度指标:及其相互关系,Reliability, Failure,h
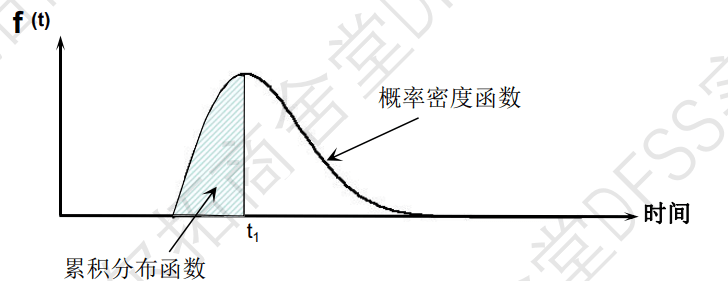
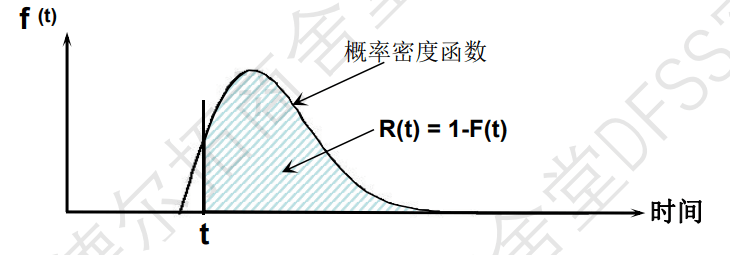
- 可靠度R(t)是(累积)存活率,
- 累积失效概率F(t)是累积死亡率(总共多少挂了),是f(t)的累积;
- 失效概率密度f(t)是单位时间单位下的死亡率;
- 瞬时失效率h(t): = f(t)/R(t),是当前存活产品中的失效率,扣除掉之前已经失效的产品;
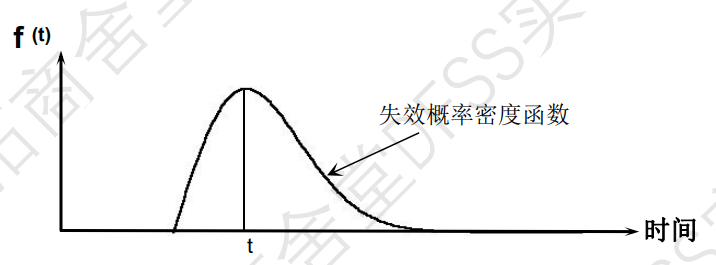

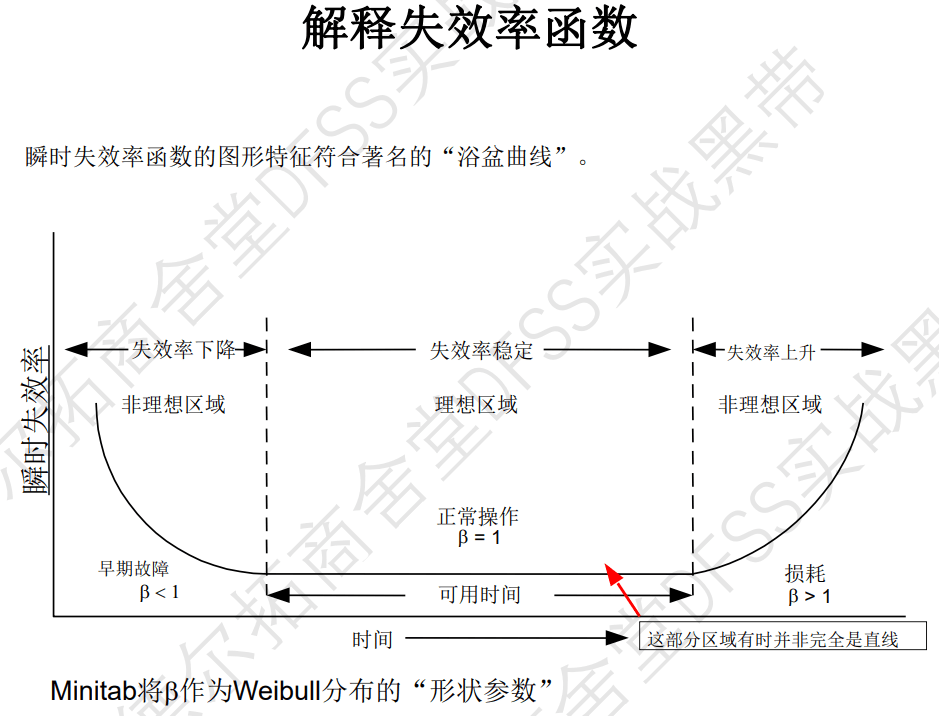
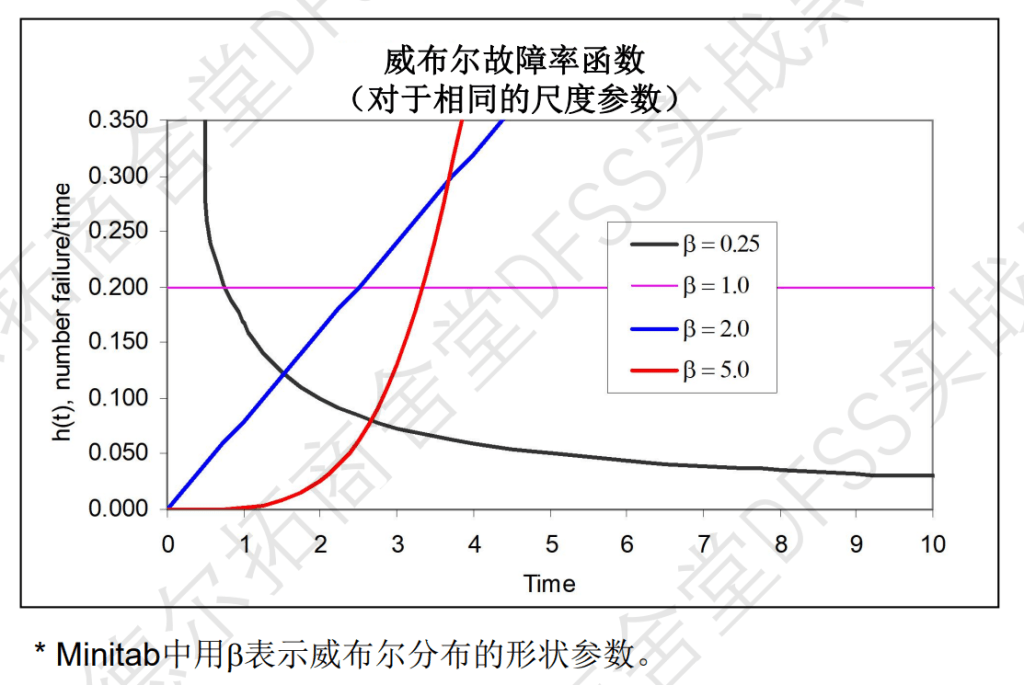
“浴盆曲线”:“瞬时失效率函数”h(t)和时间的变化
- 好的产品,“早夭期、早期故障”越短越好;
- 实战中,经常关注的是瞬时失效率h(t)
瞬时失效率h(t):
- (瞬时)失效率下降表示部件在刚开始投入使用时很容易发生故障,但是随着寿命的增加失效率会逐渐下降。
- (瞬时)失效率恒定表示部件没有或者很少磨损,随着寿命增加不大可能像新的时候那样更容易发生故障。
- (瞬时)失效率上升表示部件正在经受磨损,并且失效率也会随着寿命的增加而增加。
浴盆曲线——早期故障:
浴盆曲线——正常操作:
浴盆曲线——报废:
可靠性中的常用分布
可靠度中的常用分布,注意是针对概率密度函数f(t)的分布(单位时间下的失效率),不是浴缸曲线,不是可靠度函数R(t),
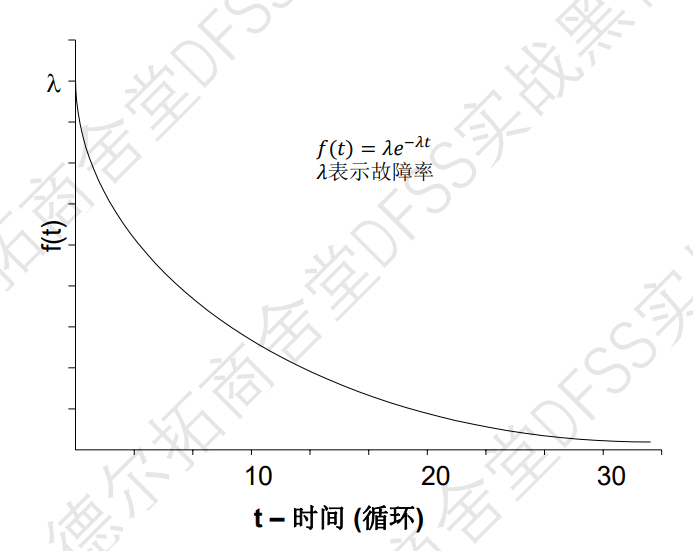
- 指数分布exponential distribution,瞬时失效率h(t)=lamda,失效密度含量f(t)符合指数分布,如果一个产品的瞬时失效率符合指数分布,就可以计算出不同的可靠性参数。比如给出
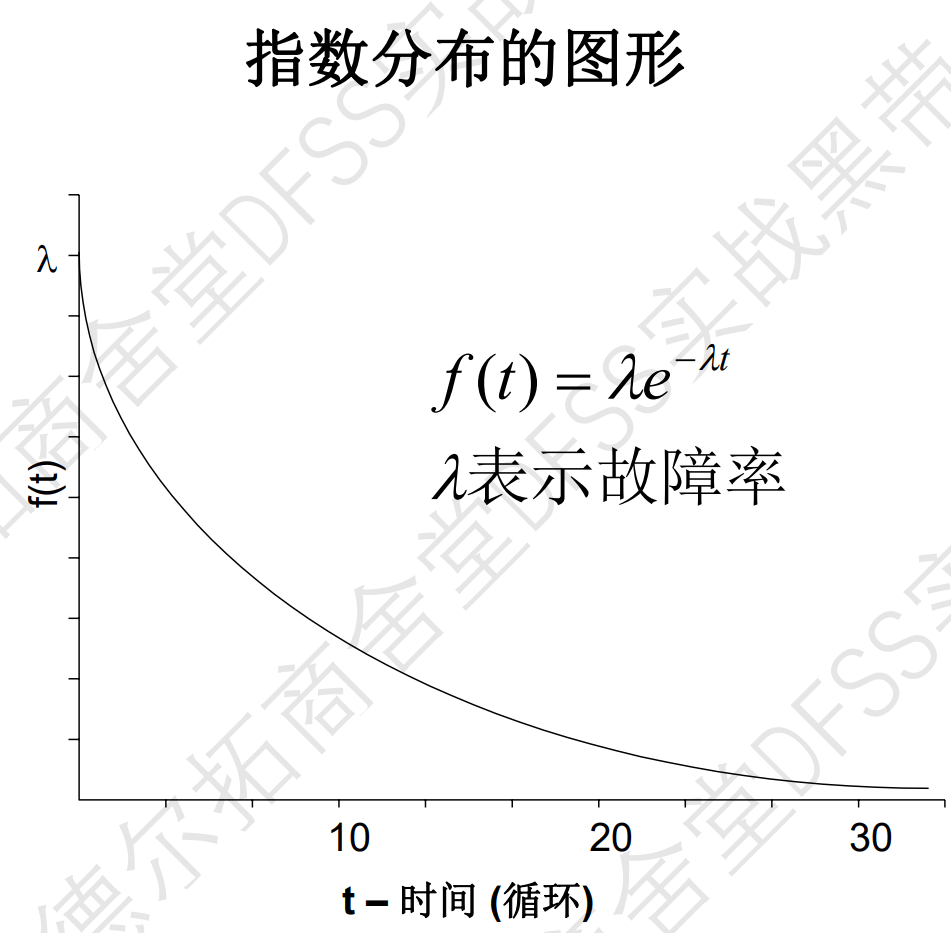

案例:
失效率水平:每100000小时发生50次失效,这是瞬时失效率h(t)(单位时间内的失效率);输入“可靠性预测.xls”,基于此该参数,计算其他可靠性指标。 比如
威布尔分布:很多种类型的分布,适用于不同类型的可靠性场景,最有用!
两参数的函数,形状参数beta(极值分布,左偏分布,右偏分布)和寿命参数alpha(和寿命相关的参数)
beta=1时,是指数分布;
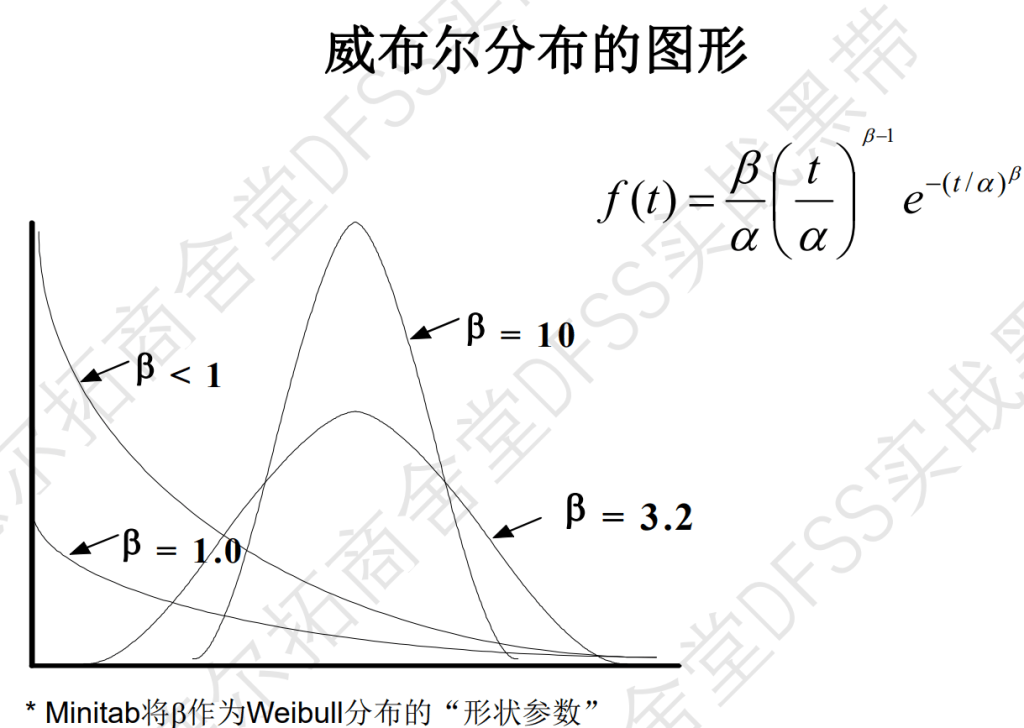


根据beta的大小,可以分析浴盆曲线中的曲线类型,特别是beta<1,和=1时分别对应的早期故障期和正常操作期的情况

案例训练:
删失数据(Censored data)
删失数据:完成测试还没有失效的样品,不知道何时会失效,失效周期在已完成的周期的右侧,因此称为“右删失”,



参数方法可靠性分析
极大似然法 vs 最小二乘法的对比:一般推荐用极大似然法。为什么? 两种方法的本质区别是什么?
如何使用minitab:分布分析——参数分布分析——删失,估计图形设置——查看90%置信区间的概率图,存活图(随时间变化的存活百分比,随时间逐渐降低到0)、累积失效概率(随时间增加最终到100%)、瞬时失效率,MTTF
DVD案例
- 用极大似然法,查看数据拟合情况,符合哪一个分布类型?
- 确定符合威布尔分布,可以先看一下“概率图”,看一下拟合的准确性如何
- 再做参数分布分析,给出不同可靠值的分布图形,比如生存图、累积失效图等;
- 还可以在minitab中设定特定日期,计算出响应的可靠值。
非参数方法可靠性分析(删失数据,非删失数据)
P95 非参数方法:如果不符合威布尔分布等常见分布,可以使用非参数方法进行可靠性数据分析。
关键词:秩统计量,
minitab:可靠性/生存——》分布分析——》非参数分布分析
最好的方法还是确保数据完整、准确,尽可能用参数分布。
2023-7-4 晚上,从头再梳理一遍到这一讲。
2023-7-6 重读删失数据和之后的参数分析、非参数分析。
第54讲-组间可靠性对比(产品、设计、供应商等)
助讲:张玮
本讲思考:可靠性对比,比之前的假设检验中的均值对比、方差对比要复杂,因为后者只是参数之间的比较。 但可靠性对比的参数是两组趋势之间的变化,对比参数是上一讲中的分布函数等。具体又可以细分成多种情况,比如两个产品之间可靠性对比,比如同一个产品的多种故障类型的对比。
本将思考:可靠性的对比,本质上还是统计参数的定量对比,比如weibull分布的形状参数和尺度参数,同时可以用概率图更直观的定性对比,比如非参数分析,可以对比期望寿命MTTF;
书中的两个案例的实际应用场景
- 组间对比:使用minitab的“通过变量”选项,对比不同的设计,不同的产品,改进前后的效果,产品与基准的对比等。(不同设计或不同产品用一个变量分组,类似下面案例1的product列,分成了K和R两款手机)
- 多故障类型:分析可靠性中的故障类型,找到最关键的故障类型(聚焦思维);
用minitab练习两个案例
案例1:手机R和更大屏幕的手机K之间的易碎性对比,数据如下,使用Minitab进行分析。
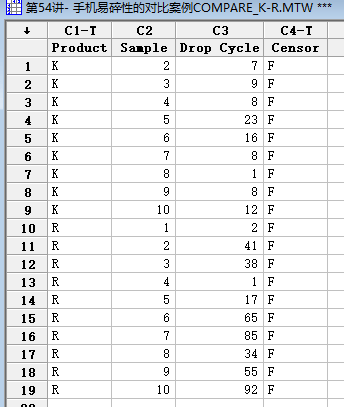
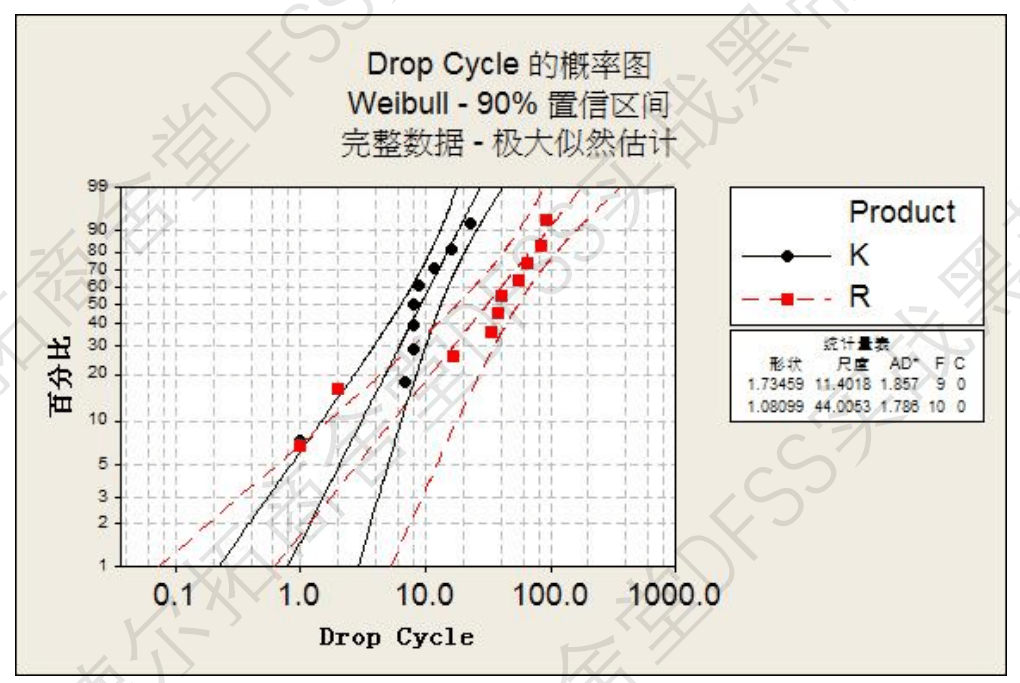
使用“参数化分布分析”,估计法选择“极大似然法”,参数估计,得到两个产品分别对应的Weibull分布的形状参数和尺度参数,然后就可以得到分布特征,比如MTTF。
R的MTTF为42 drop cycle,大于K的10次drop cycle;所以R的屏幕设计更坚固,而大屏幕的K手机不如R坚固。
问题:估计法中的最小二乘法和极大似然的区别,何时选择“极大似然”方法?
对比概率图的区间、形状参数和尺度参数,如下所示:

案例2: 多故障类型/多失效模式分析(原因之间的比较), 500件产品,测试300小时,记录测试期间出现的故障类型和故障时间,有124件完成300小时测试依然没有故障(就是sensor数据/删失数据)(一个样品可以有多个故障类型,除非第一次故障就无法运行了)。
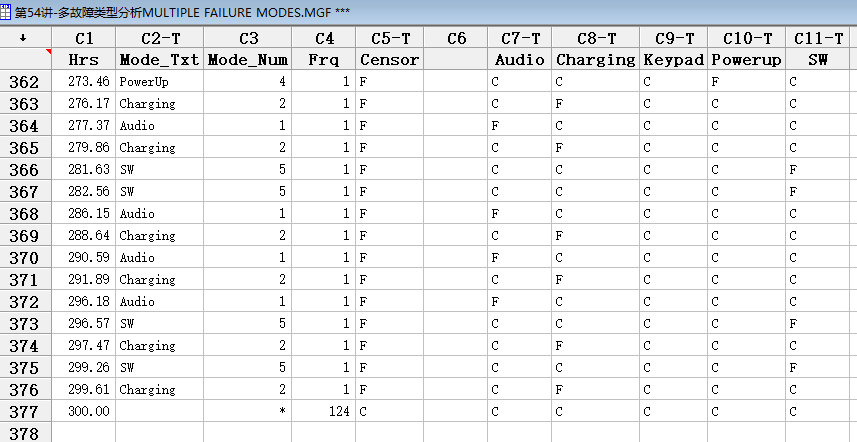
进一步分析:如果消除了失效类型中的开机和充电,产品的可靠度能改进多少;(即故障类型的占比和逻辑关系)
2023-6-18 梳理第54讲内容,还需要找时间把练习做一下。
第55讲 – 加速实验
2023-6-18 周日
主要内容:加速测试的概念,常见的加速寿命试验类型,如何使用Minitab分析加速寿命测试数据。
加速寿命测试(Accelerated life testing, ALT):评估使用条件下的可靠性,识别失效现象,避免可靠性问题。

加速寿命试验的类型:
- 增加使用频率:比如24h运行,比如键盘敲击几万次
- 加严控制条件:使用苛刻条件,比如高温高湿8585,冷热冲击、紫外老化等等
- 增加测试强度:比如增加应力,增强电压,比如屏幕静电防护测试用更高的电压
- 加严失效定义:
加速模型:
- 阿伦尼斯Arrhenius模型:化学反应基于温度的加速模型,针对采用温度作为加速变量时。
- 温度逆模型:针对温度越低失效越严重的情况?
- 自然对数模型:
- 线性模型
如何进行加速寿命试验:
提醒:设计加速实验时,要考虑失效背后的物理和化学本质。
设计加速试验,必须遵循两个原则:
- 确保实际失效模式的发生
- 不会带来新的失效模式(不改变产品失效机理)
如何选择合适的模型:经验和专业文献,失效原理,探索性实验数据
使用Minitab进行加速实验测试数据分析

案例: 绝缘材料的加速电压下的加速寿命测试,测试190,200,210,220条件下的失效寿命,然后软件分析推导出正常120V使用条件下的寿命。
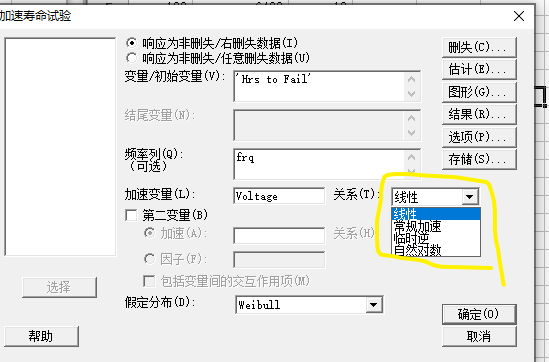
练习:工作上的寿命数据分析,如何根据40C和70C的数据点,推测常温下的peel loss。
2023-7-8 重读本讲,需要用minitab练习案例。
第56讲 系统可靠性及可用性
2023-6-18 助讲:宋明亮
可靠性知识回顾:
- 可靠度是“一定时间内的质量”, quality in a long term
- 可靠度测量:可靠度功能、期望寿命、失效率和故障率函数
- 可靠度指标:可靠度函数(可靠度Rt,失效概率密度ft,累积失效概率Ft,瞬时失效率ht,累积瞬时失效率Ht),期望寿命MTTF和MTBF(是从函数中计算出来的参数)
- 可靠度中常用分布:指数分布(函数中的故障率)、威布尔分布、正态分布、对数正态分布。
- 指数分布的图形和性质:

本讲内容:已知子系统和组件的可靠性指标,特别是MTTF和MTBF,如何分析系统(串联系统,并联系统,混联系统)整体的可靠性和可用性。
系统可靠性

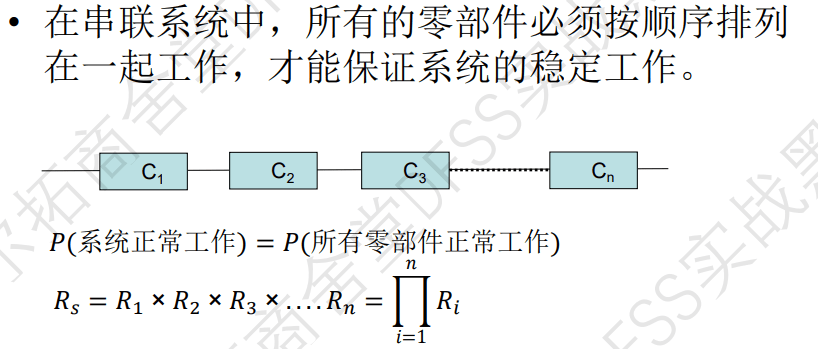
问题1: 汽车四个轮子,是串联还是并联?—》对于四个轮胎组成的系统的可靠性来说,是一个串联结构,即必须保证四个轮胎同时运行。
问题2: 汽车前面左右大灯,是串联还是并联?—》对于照明系统的可靠性来说,可以认为左右大灯是并联结构。
串联系统的可靠度:
- 串联系统的可靠度是每个系统的可靠度相乘。
- 串联系统就像串联电路,后一个部件的运行依赖于前一个部件,所以整体系统可靠性缺一不可。
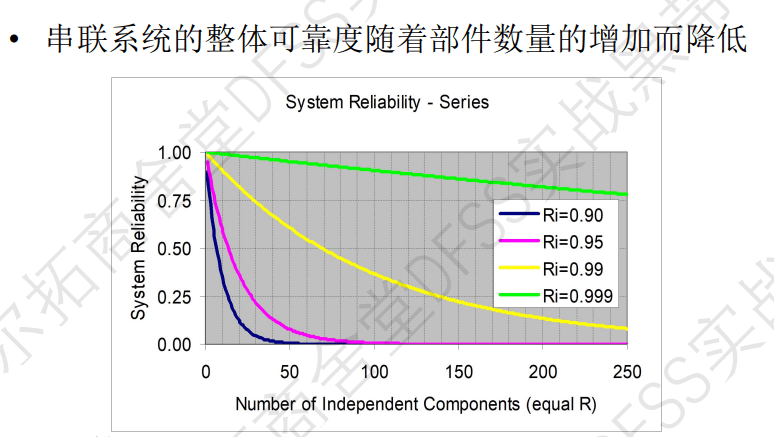
- 可靠度随着部件的增加而显著降低。
- 假定各个部件的失效服从指数分布(故障率lamda),可以计算出系统整体的可靠度,其中的lamada是子部件的故障率的和。
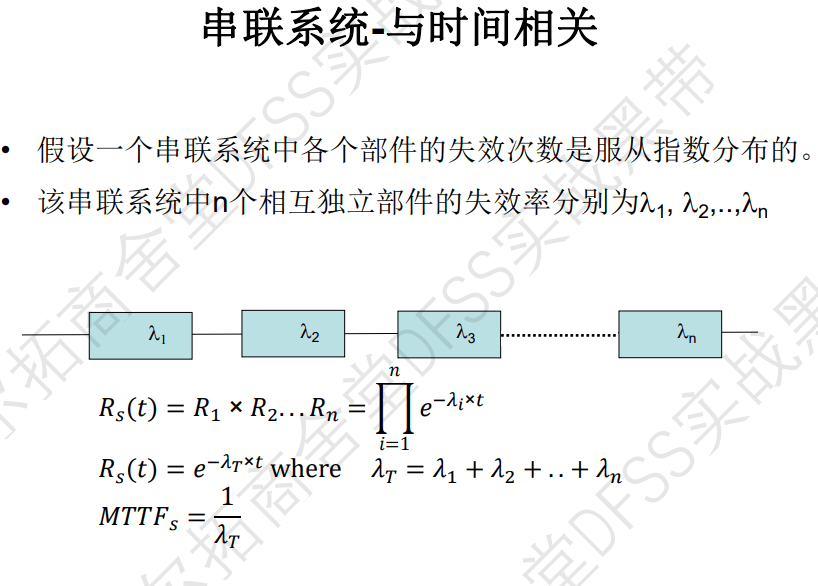
练习题:五个灯泡的串联系统,每个灯泡的故障率=1/1500=1/MTTF,计算出串联系统的故障率,然后根据指数分布,计算出灯亮100h后的可靠度是多少。 –一个基本的数学计算题,要明白可靠度含量的公式
并联系统的可靠度:
- 就像并联电路,有一个灯泡亮,电路就是通路;只有两个灯都不亮,电路才是短路。
- 只有所有并联部件全部失效,整个系统才会失效。
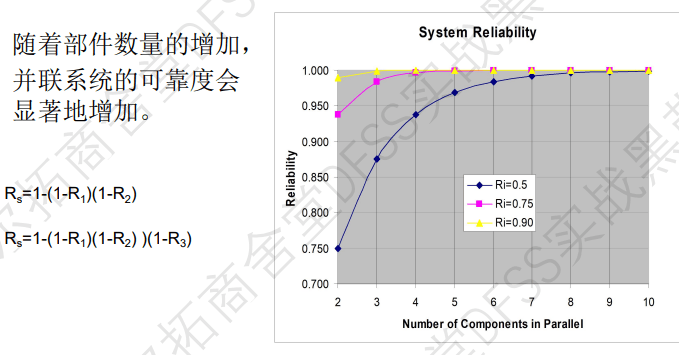
- 随着部件数量的增加,并联系统的可靠度会显著的增加。
- 计算并联系统的故障率,需要先计算所有子部件都失效时的概率,然后得到系统的可靠度。Rs=1-(1-R1)(1-R2)….
- 还是以指数分布为例,每个子系统的可靠度R=e^(-λt), 系统失效概率就是=(1-R1)(1-R2)=(1-e^(-λ1t))(1-e^(-λ2t)), 然后就可以计算出系统的可靠性Rp=1-(1-R1)(1-R2)。 假定子部件完全一样,可以直接根据子部件的失效率计算出系统的MTTF。


指数分布:
混联系统的可靠度
参考上面的并联系统和串联系统的可靠性计算过程
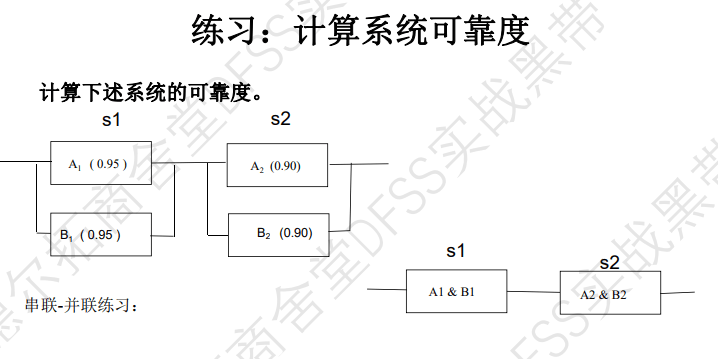
- 先计算子系统s1的可靠度,MTTF=; Rs1=1-(1-RA1)(1-RA2)=1-0.05*0.05=0.9975
- 计算子系统s2的可靠度,MTTF=; Rs2=0.99
- 计算s1和s2的串联系统的可靠度, Rs=Rs1*Rs2=0.875
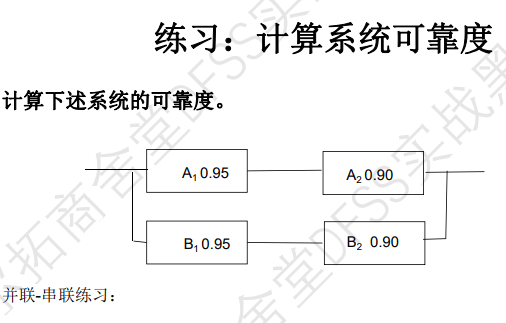
- 先并联,后串联的结构;先计算串联,再计算串联
- 上面串联Rs1=RA1*RA2=0.855
- 下面串联Rs2=0.855
- 上下并联:Rs=1-0.145*0.145=0.9790
针对更复杂的系统,不能拆解成并联和串联系统,可以用可靠度建模软件计算。
2023-6-18 上课期间总结
5 系统可用性Availability
对用户来说,可用性才是最关键的,是客户使用时间中的正常运行时间。
系统可用性:系统启动并提供客户期望的服务或功能的时间百分比。 目标是大于99.999%的系统可用性。


4NINES,停机时间=365*24*(1-0.9999)= 0.876h = 1h
计算系统可用性的几种方法:
- 根据定义计算 = 运行时间/(运行时间+停机时间)
- =MTBF/(MTBF+MTTR) = 平均故障间隔时间/(平均故障间隔时间+平均修复时间)
- 系统可用性 =
第57讲 可靠性验证及项目实施
- 欧老师开篇讲的一个案例:狭缝喷涂涂布喷嘴有颗粒和gel等,怎么办? 计算间接故障时间,冗余设计(切换清洗处理,实现不停机的保养和维修); 核心的关键参数是否符合要求,设计积分卡,设备的关键参数,怎么算达到目标,如何算验证的计划;可靠性设计等。
- 可靠性验证,有点像我现在工作中做的pilot trial和对应的样品性能分析。
- 2023-6-21”退化分析“,今天同事讲,某一款胶带在RT,40C和70C下,gel content会逐渐增加,我们把50%作为失效指标,确认常温24month是产品的shelf time,因为超过24month,gel content就超过了50%。与之对应,40C和70C都能有更快的退化曲线,这就是一个很好的可靠性分析和加速寿命分析;但使用的gel content并不是一个失效与否的属性变量,而是一个反映产品退化状态的连续变量。可以用退化分析进行专门研究。
本讲内容:
- 如何验证新产品的可靠性是否达到目标?这是计算可靠度的逆过程,可靠性分析是根据可靠性测试数据计算可靠度,而可靠性验证是根据预期的(特定测试时长下的)可靠度计算验证计划,特别是取样次数,
试验时长等。 - 一共有三种可靠性验证的方法,全部通过试验(计算出最少取样量,全部通过可靠度测试;具体又分为参数方法,直接用参数分布计算;和非参数方法),加速寿命试验(如何根据寿命曲线设计加速寿命试验的样本分布),退化试验(使用反映退化状态的变量)
三种试验验证方法:
- 方法1:全部通过试验 (达到特定置信水平比如95%时的抽样量)
- 方法2:寿命试验
- 方法3:退化实验
方法1:全通过试验–非参数方法
运行验证试验,根据可靠度目标计算最少测试产品数量,运行确认是否能通过可靠性验证。需要使用以下的近似公式,计算全数通过试验的所需样本量。


方法1: 全数通过试验——参数方法
参数方法:即分布符合特定的分布类型,比如失效分布符合威布尔分布,就可以计算出验证试验需要的样本量。
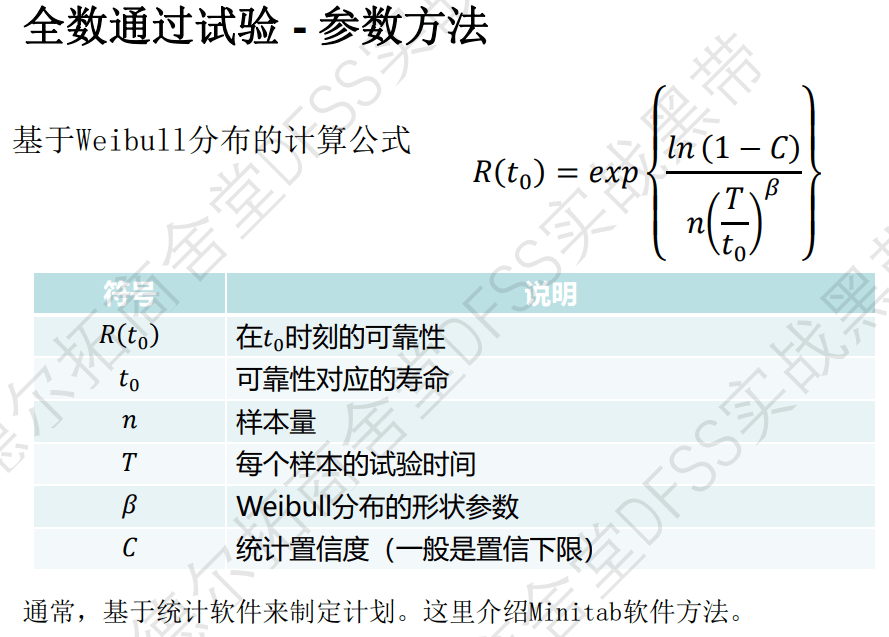
本质:已知函数关系,输入哪些变量,计算出哪些待设定的变量。
思考:这就是一个简单的数据计算,以下公式一共有6个变量,我们需要样本量n和对应的试验时间T(这两个变量可以描绘成一条曲线,供实验者选择),这样就需要提前输入剩余的四个变量:可靠度、形状参数、统计置信度、可靠度对应的寿命;这四个变量还有一些替代,比如可靠度指标还可以用MTTF等。

直接使用Minitab进行验证试验: 可靠性——试验方案——验证。
案例:根据案例信息的五个信息,计算出需要的样本量。
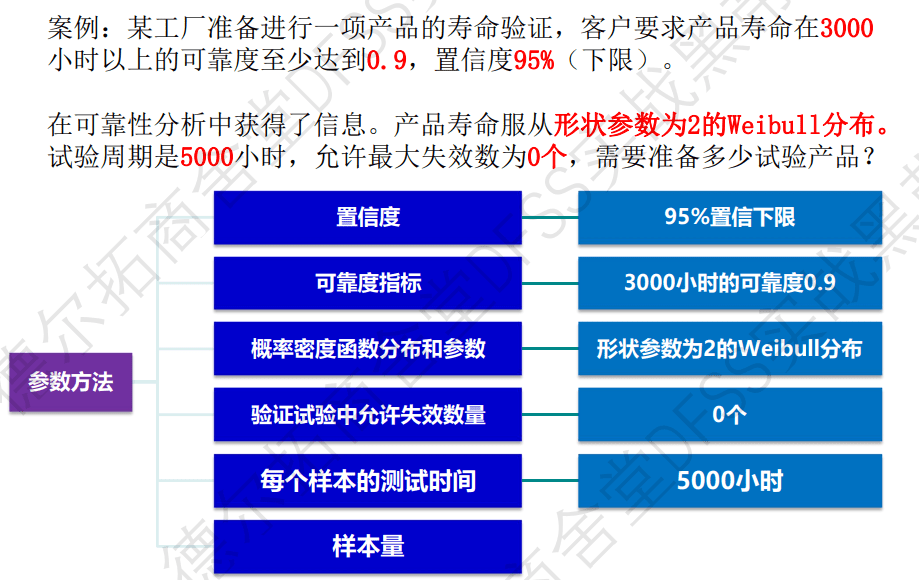
答案:使用minitab软件计算,实验样本量N=11,需要运行5000小时,如果都没有失效,通过可靠性验证。(已知“每个单元的检验时间即5000h,计算”样本数量“)
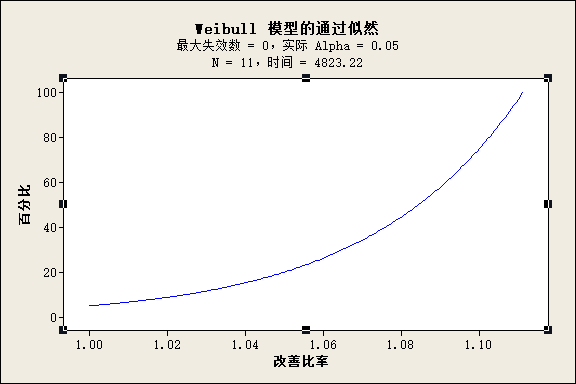
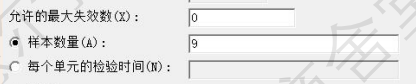
如果测试到2000h时,发现2个已经坏了,就重新计算实际样本量N=9(放弃两个已经失效的)时,需要运行多长时间才能通过可靠性验证,用Minitab重新计算(已知”样本数量“,计算”每个单元的检验时间“),答案是剩下的9个样品,需要计算运行5332-2000=3332小时。
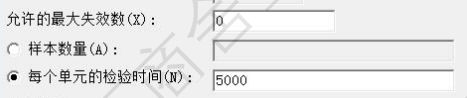
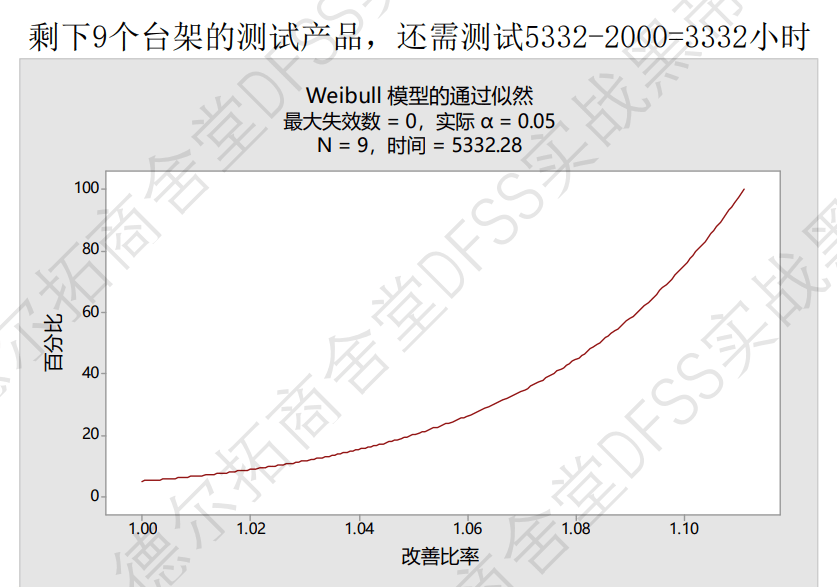
问题:上图的横纵坐标(改善比率,百分比)是什么意思?
答案:如果验证试验没有通过(比如11个样品,有两个样品只运行了2000h),需要延长测试时间的比率,(5332-2000)/2000=1.1,如果剩余的9个都通过了5332h验证,那么系统通过可靠性验证的概率是改善比率1.1对应的纵坐标。
改善率曲线:减少测试样本量,追加测试时间; 改善率=3332/2000=1.1,对应下图得到追加试验下通过验证的概率。【怎么感觉这个解释有问题呢,非常有问题。】
补充分析:在软件中选择计算样本数量从1到12,需要的测试时长

结果如下:选取的样本量越多,需要的测试时长越短,反之亦然。这里的改善比例是什么意思?
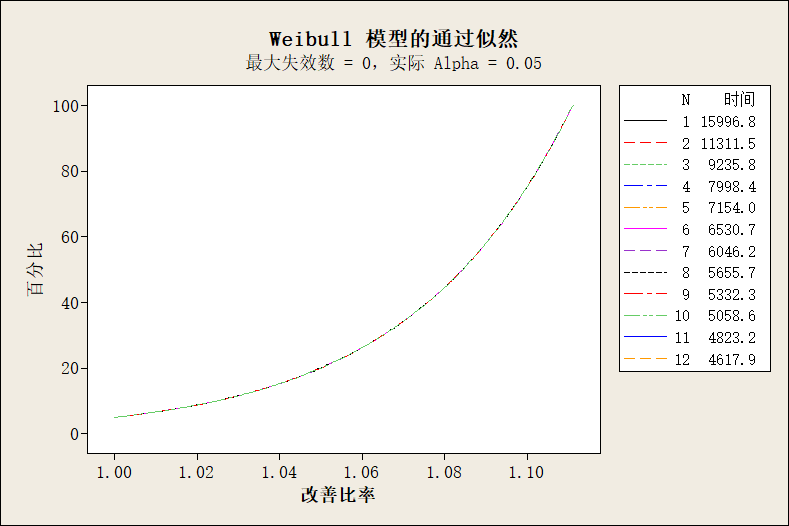
正确答案:来自《基于Minitab的现代实用统计》p409: 改善比率是真实值与要检验的最小值的比。真实值是验证实验中实际要测试的时长比如5000h,而要检验的最小值,(我猜测)一般定义为”5%失效的时间“。如果我们知道改进前系统的检验最小值,然后根据改善比例(比如5%失效对应5000h),那么实际测试到5500h时(改善比例1.1),就有大约80%概率通过验证;如果实际测试到了6000h(改善比率1.2),那可以接近100%确认通过验证。
方法2: 寿命试验方法
- 常规寿命:常规条件下进行试验,通过寿命数据分析,得出可靠性指标,产品的寿命分布和失效类型等。
- 加速寿命:在加速条件下测试,提前要有加速条件下的失效分布情况,然后根据有限的样本量确定如何进行加速试验。
- 退化试验:研究随时间而退化的产品性能,退化到特定临界值就认为失效了。(比如胶带的内聚力增加到特定水平;比如胶带的凝胶量增加到特定水平,就视为产品失效。)
方法3: 退化分析
退化:有的产品的性能是随性能退化,当性能指标超过某个指标时,视为失效。
以特征值的变化,来表征是否失效。把属性变量(失效,未失效)转化成特性值的连续性变化。
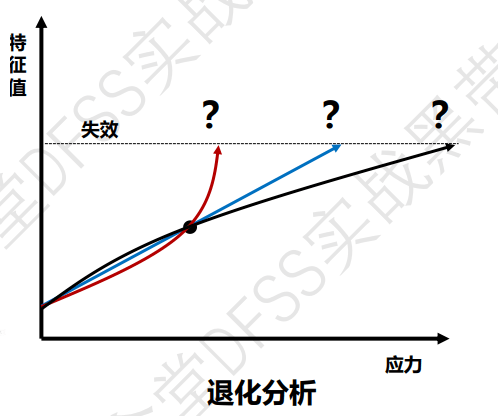
2023-7-9 研究第57讲,特别是”改善比率”,有不少疑问。
———————————————-
六西格玛可靠性设计
如果解决的问题本身就是可靠性问题,就需要使用这儿的15 steps和模板。
第58讲 验证关键客户需求CCR的实现 (5.2)
2023-6-28 袁金玲老师助讲
之前的内容都是5.1 可靠性预测;本讲是5.2 “验证关键客户需求CCR的实现”,
关键主题:能力流图,产品计分卡。
思考:设计计分卡,能力流下树,这些主要用于系统级的产品,产品有很多子系统和组件,平级之间有很少的交互作用,不然就像配方开发有很多的交互作用;更多是树形图的主机展开,很少有复杂的交叉和多多对应。
P17 结合功能图,展开参数流下树。
三种整理能力流图的方法:物理流下树,功能框图,QFD
第59讲 实战拓展 (暂略)
第60讲 验证学习目标的实现(6.3)
2023-7-9 先发布,还缺最后三讲没有回顾整理。