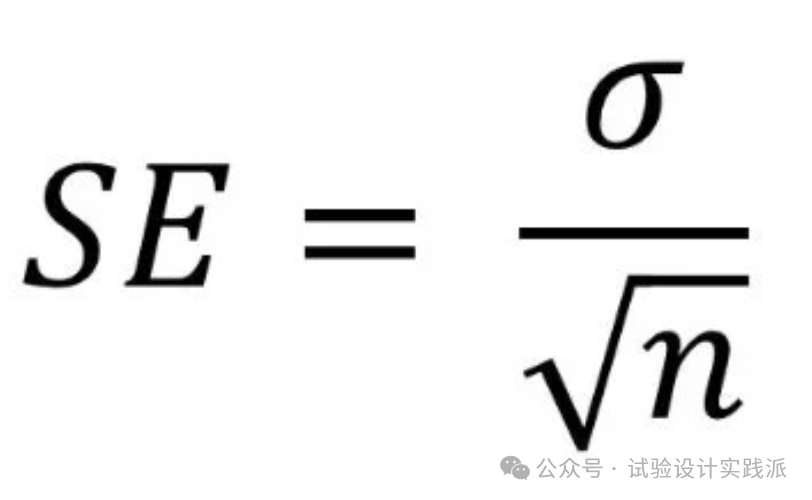To distinguish between the sample and population quantities, η is called the population mean and ȳ the sample average. A parameter like the mean η is a quantity directly associated with a population. A statistic like the average ȳ is a quantity calculated from a set of data often thought of as some kind of sample taken from the population.
标准差 standard deviation,SD工程师对标准差这个统计术语并不陌生,我们使用标准差度量一堆数据的离散程度,在excel中也很容易使用函数stdev()计算出样本的标准差。在DoE中,我们计算出残差表,就可以计算残差标准差,进而量化残差的离散程度(spread)。但是可以说,标准差就是统计量吗?未必如此!简单来说,标准差既可以是统计量(样本的标准差),又可以是参数(总体的标准差);详细答案见DoE基础:为何是“参数检验”而非“统计量检验”?而这两者之间的联系,就是“统计推断”:基于样本推断总体。当我们说用样本的标准差去估计总体的标准差时,这就是用样本统计量去估计总体参数的典型例子,具体估计方法就是下面要提到的 one more thing。标准误 standard error,SE来到了最难的概念,标准差度量的是数据的离散程度,标准误度量的是什么?“统计量的标准差,称为标准误”;以残差为例,“残差标准差的标准差,称为标准误”,为什么残差标准差还有一个标准差? 答案是经常被忽略的“重复抽样”。第一个标准差是样本内的标准差,即样本数据点的离散程度;第二个标准差是样本间的标准差,重复抽样,计算出每个多个样本的标准差,再计算这些标准差的标准差;结果被称为“标准误”。因此,标准误衡量的是统计量的抽样误差,即如果重复做实验,该估计量的波动大小(离散程度),也就是之前所说的试验精度——我只做一次试验,试验结论能不能被重复出来?再换个角度,“统计量的标准差,称为标准误”,这儿的“标准差”是统计量而非参数,所以我的一个不严谨的说法是,标准误是统计量的统计量,包含了两层统计。
为什么要用error(误差、偏差)这个名字呢?标准差(standard deviation),关注数据本身,度量数据的离散程度,不直接涉及比较或推断;标准误(standard error),强调统计量的偏差——重复抽样或重复试验之间,反映了试验的精度;隐含着比较和推断,这就是为什么用error一词。而实际上,计算标准误的目的就是用来比较,《试验设计》:试验精度中介绍了如何使用标准误,分析区组之间、处理之间是否存在显著性差异;这就是典型的统计推断。一句话总结,error中包含了比较,但deviation并没有。One More thing不论是“统计量的标准差,称为标准误”,还是“重复抽样”,这儿都隐含了一个关键的统计术语或统计定理:中心极限定理。这是DoE中最有用的一个定理,也是连接“标准差”和“标准误”的桥梁。如果弄明白了中心极限定理,就可以更深刻的理解标准差和标准误,以及重复抽样等概念。文章已经太长了,这篇的知识密度已经偏高了,此处留个引子,以后再展开。相关历史文章:DoE基础:为何是“参数检验”而非“统计量检验”?《试验设计》:试验精度DoE经典图书推荐:《试验设计》无重复析因试验怎么分析?——摩托罗拉波焊案例的延伸思考